搜索到
4
篇与
的结果
-
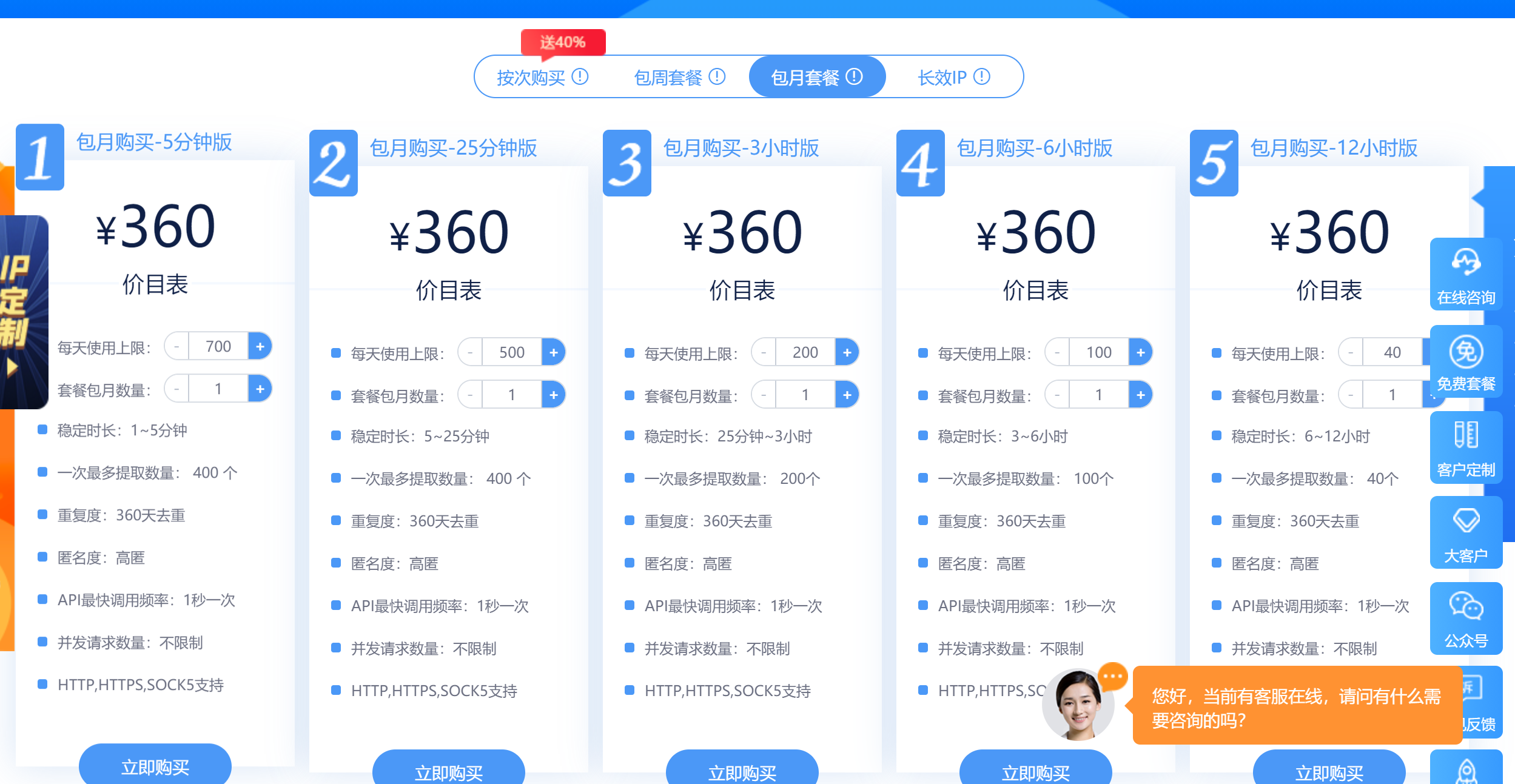
![Python使用芝麻代理维护一个健康可用的IP池]() Python使用芝麻代理维护一个健康可用的IP池 最近有个需求要用Python做一个爬虫不间断运行,但是对方网站做了比较严格的反爬,然后就选择了用随机header和代理。刚开始的时候使用的免费代理,后来发现免费才是最贵的,经常失效或者连接不上,于是改为使用付费代理,最后选择了芝麻代理但是爬虫每秒请求可能为5QPS左右,芝麻代理默认请求为1QPS,所以只能采取维护一个代理池的方式,每次请求从中随机选取。刚开始的时候使用的是购买套餐,后来发现并不划算,套餐每天有使用上限,IP存活时间长的,上限数量就低,IP上限高的,存活时间又比较低,有预算上限的长时间爬虫类项目可以选择IP存活时间长的套餐,把维护IP池数量稍微降低一点,勉强够用一天了。不过后期还是建议使用按次购买,控制好频率就不怕超限。注意IP获取不计次,但是一旦使用就会计次之前没经验选择5分钟套餐,不到两点IP用量就要到上限了,选套餐还是建议存活时间长的这个维护IP池同时支持套餐和按次收费,所以也不用太过纠结首先你要获取到你的AppKey和Neek参数,在官网提取IP生成的API链接里可以获取到http://h.zhimaruanjian.com/getapi/#obtain_ip如果是选择的用套餐提取,还会有对应的pack参数,是你自己的对应套餐ID,在上面的链接同样可以获取到,然后实例化时把参数填进去即可。pack为0则按次提取IP这里我们按照维护大小为50个的IP池为例,使用示例如下:while True: try: begin = time.time() * 1000 zm = ZhiMaPool('You App Key', 'Your Neek') # 你的AppKey的Neek参数 zm.ip_sum = 50 # IP池总数量 # zm.pack = 121888 # 套餐pack参数,为0则使用按次提取,默认为0 # zm.ip_type = 'http' # http or https # zm.ttl = 60 # 过期提前失效时间,默认提前60秒 # zm.pool_path = './zhima_pool.json' # IP池保存路径 zm.check_ip() cost = time.time() * 1000 - begin print('本次耗时'+ str(cost) + '毫秒') time.sleep(30) # 间隔时间请少于ttl时长 except Exception as e: print(e)完整代码# -*- coding: utf-8 -*- # __author__ = "Yuuuu" gty0211@foxmail.com # Date: 2020-10-22 Python: 3.8 import os import time import requests import json import re class ZhiMaPool(object): pool_path = './zhima_pool.json' # IP池保存地址 ttl = 60 # 过期间隔 pack = 0 # 套餐pack参数,为0则使用按次提取 ip_pool = [] ip_type = 'http' # 提取IP类别,http或者https ip_sum = 100 # IP池总数 def __init__(self,key,neek,ip_sum = 100,ttl = 60): self.key = key self.neek = neek self.ttl = ttl self.ip_sum = ip_sum self._init() # init the proxy def _init(self): print('初始化中...') if os.path.exists(self.pool_path): with open(self.pool_path,'r') as f: self.ip_pool = json.loads(f.read()) response = requests.get('http://pv.sohu.com/cityjson?ie=utf-8') address = re.search(r'"cip": "(.*?)", "cid', response.text).group(1) # add ip_white url = 'http://web.http.cnapi.cc/index/index/save_white?neek={neek}&appkey={key}&white={local}'.format( neek=self.neek, key=self.key, local=address) response = requests.get(url=url) code = json.loads(response.text).get('code') if code == 0 or code == 115: print('初始化成功,启动中稍等..') else: print('初始化芝麻账号失败') time.sleep(2) def check_ip(self): for index,node in enumerate(self.ip_pool): ip = node[0] port = node[1] expire_time = node[2] if expire_time - self.ttl < time.time(): del self.ip_pool[index] print('IP即将超时,已删除',ip) if not self.checkproxy(ip + ':' + port,ip): del self.ip_pool[index] # 删除 print('使用IP代理请求出错,删除',ip) while len(self.ip_pool) < self.ip_sum: if self.pack == 0: self.add_ip_count() else: self.add_ip() time.sleep(2) # 不能请求太快 self.save_to_file() # 存到json文件 # 根据套餐提取 def add_ip(self, num=20): port = '11' if self.ip_type == 'https' else '1' # http(default) & https get_url = 'http://webapi.http.zhimacangku.com/getip?num={num}&type=2&pro=&city=0&yys=0&port={port}&pack={pack}&ts=1&ys=0&cs=0&lb=1&sb=0&pb=4&mr=1®ions='.format(port=port,num=num,pack=self.pack) response = requests.get(get_url) # code = json.loads(response.text).get('code') self.parse(response.text) # 按次提取IP num:每次提取数量,invalid:有效时长 TODO 这里可以修改为其他 def add_ip_count(self, num=20, invalid_time=2): port = '11' if self.ip_type == 'https' else '1' # http(default) & https get_url = 'http://webapi.http.zhimacangku.com/getip?num={num}&type=2&pro=&city=0&yys=0&port={port}&time={invalid_time}&ts=1&ys=0&cs=0&lb=1&sb=0&pb=4&mr=1®ions='.format(num=num,invalid_time=invalid_time,port=port) response = requests.get(get_url) self.parse(response.text) # 解析提取的IP def parse(self, json_data): count = 0 ret_dict = json.loads(json_data) if ret_dict.get('success'): nodes = ret_dict.get('data') for node in nodes: expire_time = self.str_to_time(node.get('expire_time')) if expire_time - self.ttl < time.time(): print('该IP存活时间过短,已弃用',node.get('ip')) continue tmp = [[str(node.get('ip')),str(node.get('port')),expire_time,self.ip_type]] self.ip_pool.extend(tmp) # 添加到ip池 count += 1 print('本次获取' + str(count) + '个IP') # 时间字符串转时间戳 def str_to_time(self, time_str): # 先转换为时间数组 timeArray = time.strptime(time_str, "%Y-%m-%d %H:%M:%S") # 转换为时间戳 timeStamp = int(time.mktime(timeArray)) return timeStamp # 检查代理IP有效性 def checkproxy(self,proxy,ip): return True # response = requests.get('http://pv.sohu.com/cityjson?ie=utf-8',proxies={self.ip_type:proxy}) # address = re.search(r'"cip": "(.*?)", "cid', response.text).group(1) # time.sleep(2) # return str(address) == str(ip) def save_to_file(self): with open(self.pool_path, 'w') as f: f.write(json.dumps(self.ip_pool)) # 使用方法 while True: try: begin = time.time() * 1000 zm = ZhiMaPool('You App Key', 'Your Neek') zm.ip_sum = 50 # IP池总数量 # zm.pack = 121888 # 套餐pack参数,为0则使用按次提取,默认为0 # zm.ip_type = 'http' # http or https # zm.ttl = 60 # 过期提前失效时间,默认提前60秒 # zm.pool_path = './zhima_pool.json' # IP池保存路径 zm.check_ip() cost = time.time() * 1000 - begin print('本次耗时'+ str(cost) + '毫秒') time.sleep(30) # 间隔时间请少于ttl时长 except Exception as e: print(e) 后台运行nohup python3 ZhiMaProxy.py >/dev/null 2>log & 即可在同目录下的zhima_pool.json文件得到一个健康的IP池重复一遍,获取IP不收费,使用才收费
Python使用芝麻代理维护一个健康可用的IP池 最近有个需求要用Python做一个爬虫不间断运行,但是对方网站做了比较严格的反爬,然后就选择了用随机header和代理。刚开始的时候使用的免费代理,后来发现免费才是最贵的,经常失效或者连接不上,于是改为使用付费代理,最后选择了芝麻代理但是爬虫每秒请求可能为5QPS左右,芝麻代理默认请求为1QPS,所以只能采取维护一个代理池的方式,每次请求从中随机选取。刚开始的时候使用的是购买套餐,后来发现并不划算,套餐每天有使用上限,IP存活时间长的,上限数量就低,IP上限高的,存活时间又比较低,有预算上限的长时间爬虫类项目可以选择IP存活时间长的套餐,把维护IP池数量稍微降低一点,勉强够用一天了。不过后期还是建议使用按次购买,控制好频率就不怕超限。注意IP获取不计次,但是一旦使用就会计次之前没经验选择5分钟套餐,不到两点IP用量就要到上限了,选套餐还是建议存活时间长的这个维护IP池同时支持套餐和按次收费,所以也不用太过纠结首先你要获取到你的AppKey和Neek参数,在官网提取IP生成的API链接里可以获取到http://h.zhimaruanjian.com/getapi/#obtain_ip如果是选择的用套餐提取,还会有对应的pack参数,是你自己的对应套餐ID,在上面的链接同样可以获取到,然后实例化时把参数填进去即可。pack为0则按次提取IP这里我们按照维护大小为50个的IP池为例,使用示例如下:while True: try: begin = time.time() * 1000 zm = ZhiMaPool('You App Key', 'Your Neek') # 你的AppKey的Neek参数 zm.ip_sum = 50 # IP池总数量 # zm.pack = 121888 # 套餐pack参数,为0则使用按次提取,默认为0 # zm.ip_type = 'http' # http or https # zm.ttl = 60 # 过期提前失效时间,默认提前60秒 # zm.pool_path = './zhima_pool.json' # IP池保存路径 zm.check_ip() cost = time.time() * 1000 - begin print('本次耗时'+ str(cost) + '毫秒') time.sleep(30) # 间隔时间请少于ttl时长 except Exception as e: print(e)完整代码# -*- coding: utf-8 -*- # __author__ = "Yuuuu" gty0211@foxmail.com # Date: 2020-10-22 Python: 3.8 import os import time import requests import json import re class ZhiMaPool(object): pool_path = './zhima_pool.json' # IP池保存地址 ttl = 60 # 过期间隔 pack = 0 # 套餐pack参数,为0则使用按次提取 ip_pool = [] ip_type = 'http' # 提取IP类别,http或者https ip_sum = 100 # IP池总数 def __init__(self,key,neek,ip_sum = 100,ttl = 60): self.key = key self.neek = neek self.ttl = ttl self.ip_sum = ip_sum self._init() # init the proxy def _init(self): print('初始化中...') if os.path.exists(self.pool_path): with open(self.pool_path,'r') as f: self.ip_pool = json.loads(f.read()) response = requests.get('http://pv.sohu.com/cityjson?ie=utf-8') address = re.search(r'"cip": "(.*?)", "cid', response.text).group(1) # add ip_white url = 'http://web.http.cnapi.cc/index/index/save_white?neek={neek}&appkey={key}&white={local}'.format( neek=self.neek, key=self.key, local=address) response = requests.get(url=url) code = json.loads(response.text).get('code') if code == 0 or code == 115: print('初始化成功,启动中稍等..') else: print('初始化芝麻账号失败') time.sleep(2) def check_ip(self): for index,node in enumerate(self.ip_pool): ip = node[0] port = node[1] expire_time = node[2] if expire_time - self.ttl < time.time(): del self.ip_pool[index] print('IP即将超时,已删除',ip) if not self.checkproxy(ip + ':' + port,ip): del self.ip_pool[index] # 删除 print('使用IP代理请求出错,删除',ip) while len(self.ip_pool) < self.ip_sum: if self.pack == 0: self.add_ip_count() else: self.add_ip() time.sleep(2) # 不能请求太快 self.save_to_file() # 存到json文件 # 根据套餐提取 def add_ip(self, num=20): port = '11' if self.ip_type == 'https' else '1' # http(default) & https get_url = 'http://webapi.http.zhimacangku.com/getip?num={num}&type=2&pro=&city=0&yys=0&port={port}&pack={pack}&ts=1&ys=0&cs=0&lb=1&sb=0&pb=4&mr=1®ions='.format(port=port,num=num,pack=self.pack) response = requests.get(get_url) # code = json.loads(response.text).get('code') self.parse(response.text) # 按次提取IP num:每次提取数量,invalid:有效时长 TODO 这里可以修改为其他 def add_ip_count(self, num=20, invalid_time=2): port = '11' if self.ip_type == 'https' else '1' # http(default) & https get_url = 'http://webapi.http.zhimacangku.com/getip?num={num}&type=2&pro=&city=0&yys=0&port={port}&time={invalid_time}&ts=1&ys=0&cs=0&lb=1&sb=0&pb=4&mr=1®ions='.format(num=num,invalid_time=invalid_time,port=port) response = requests.get(get_url) self.parse(response.text) # 解析提取的IP def parse(self, json_data): count = 0 ret_dict = json.loads(json_data) if ret_dict.get('success'): nodes = ret_dict.get('data') for node in nodes: expire_time = self.str_to_time(node.get('expire_time')) if expire_time - self.ttl < time.time(): print('该IP存活时间过短,已弃用',node.get('ip')) continue tmp = [[str(node.get('ip')),str(node.get('port')),expire_time,self.ip_type]] self.ip_pool.extend(tmp) # 添加到ip池 count += 1 print('本次获取' + str(count) + '个IP') # 时间字符串转时间戳 def str_to_time(self, time_str): # 先转换为时间数组 timeArray = time.strptime(time_str, "%Y-%m-%d %H:%M:%S") # 转换为时间戳 timeStamp = int(time.mktime(timeArray)) return timeStamp # 检查代理IP有效性 def checkproxy(self,proxy,ip): return True # response = requests.get('http://pv.sohu.com/cityjson?ie=utf-8',proxies={self.ip_type:proxy}) # address = re.search(r'"cip": "(.*?)", "cid', response.text).group(1) # time.sleep(2) # return str(address) == str(ip) def save_to_file(self): with open(self.pool_path, 'w') as f: f.write(json.dumps(self.ip_pool)) # 使用方法 while True: try: begin = time.time() * 1000 zm = ZhiMaPool('You App Key', 'Your Neek') zm.ip_sum = 50 # IP池总数量 # zm.pack = 121888 # 套餐pack参数,为0则使用按次提取,默认为0 # zm.ip_type = 'http' # http or https # zm.ttl = 60 # 过期提前失效时间,默认提前60秒 # zm.pool_path = './zhima_pool.json' # IP池保存路径 zm.check_ip() cost = time.time() * 1000 - begin print('本次耗时'+ str(cost) + '毫秒') time.sleep(30) # 间隔时间请少于ttl时长 except Exception as e: print(e) 后台运行nohup python3 ZhiMaProxy.py >/dev/null 2>log & 即可在同目录下的zhima_pool.json文件得到一个健康的IP池重复一遍,获取IP不收费,使用才收费 -
![在windows用python自动备份数据库]() 在windows用python自动备份数据库 模板和linux上备份差不多,但是windows上有些命令不通用#!/usr/bin/env python # -*- coding: utf-8 -*- import os import time user = 'root' # 数据库帐号 passwd = 'passwd' # 密码 database = 'picking' # 要备份的数据库名称 if not os.path.exists('C:\PHP\sql\\'+database): os.mkdir('C:\PHP\sql\\'+database) while True: os.chdir('C:\PHP\sql\\'+database) xyFile = database+'-'+ time.strftime('%Y-%m-%d',time.localtime(time.time())) + '.sql' os.system("mysqldump -u"+user+" --password="+passwd+" "+database+" >"+xyFile) time.sleep(86400)
在windows用python自动备份数据库 模板和linux上备份差不多,但是windows上有些命令不通用#!/usr/bin/env python # -*- coding: utf-8 -*- import os import time user = 'root' # 数据库帐号 passwd = 'passwd' # 密码 database = 'picking' # 要备份的数据库名称 if not os.path.exists('C:\PHP\sql\\'+database): os.mkdir('C:\PHP\sql\\'+database) while True: os.chdir('C:\PHP\sql\\'+database) xyFile = database+'-'+ time.strftime('%Y-%m-%d',time.localtime(time.time())) + '.sql' os.system("mysqldump -u"+user+" --password="+passwd+" "+database+" >"+xyFile) time.sleep(86400) -
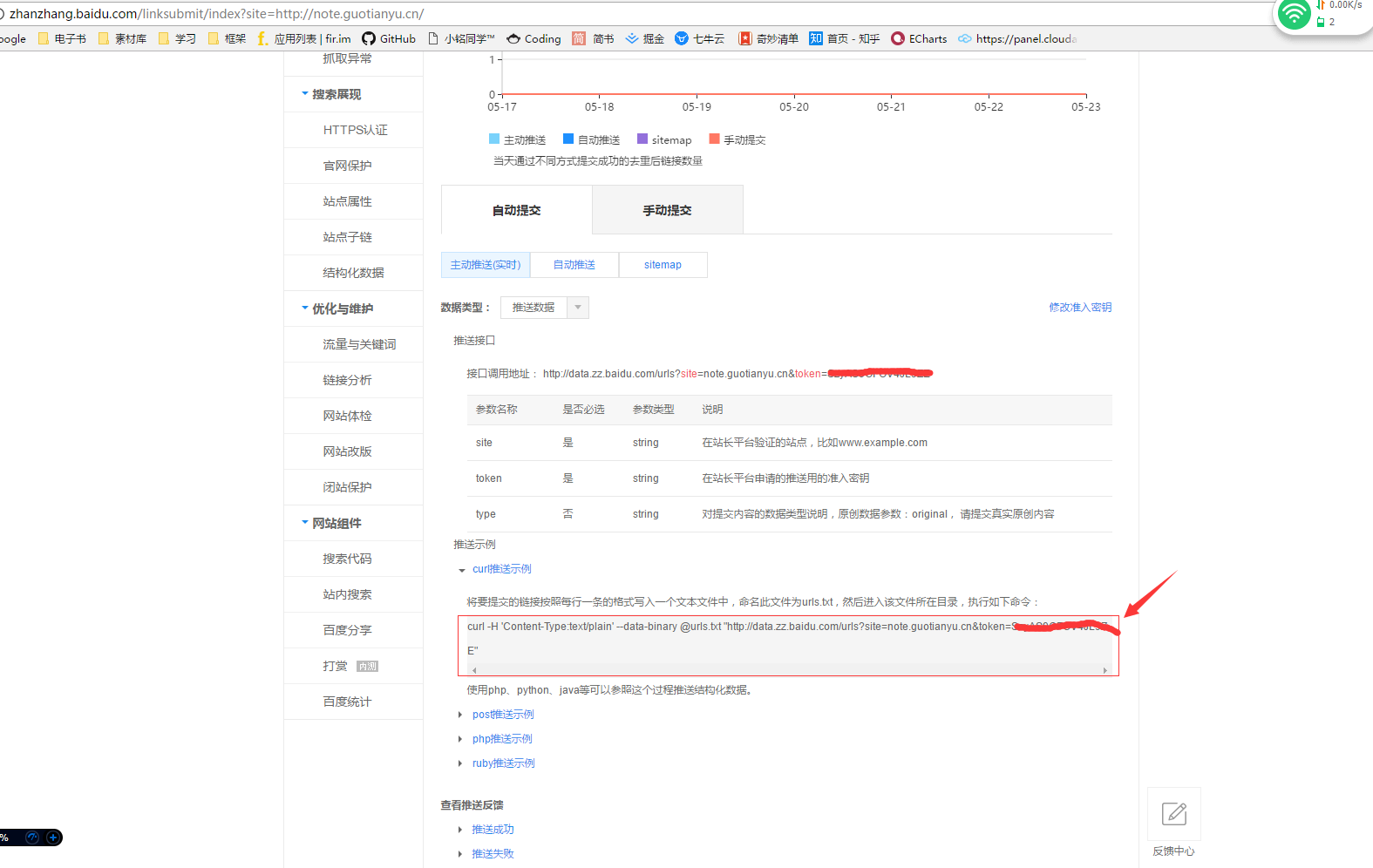
![Python自动化实现主动推送站点到百度]() Python自动化实现主动推送站点到百度 在百度站长平台中,有各种方式可以提交自己的站点,以提高百度抓取自己网站的效率。此文章旨在使用主动推送(实时)提交到百度站长平台以提高网站曝光率。此方法是使用curl推送,所以在这里找到你的示例命令(前提是你要成为站长)然后我是在Linux上面执行的Python,其他平台此方法不适用。找个你喜欢的目录新建一个你喜欢的文件夹文件结构其实一共就两个文件,还有一个是自动生成的curl.py #用来执行自动推送geturl.py #抓取网站所有链接urls.txt #保存抓取的网站链接其中urls.txt是在执行 geturls.py 后自动生成,用以保存你要推送网站的所有链接代码curl.py#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 17/02/28 下午9:44 import os import time while True: ###### cmd = "你在百度站长中看到的curl推送示例命令" ###### cmd = "curl -H \'Content-Type:text/plain\' --data-binary @urls.txt \"http://data.zz.baidu.com/urls?site=note.coccoo.cc&token=xxxxxxxxxxxxxxx\"" os.system(cmd) # 休息间隔为 1s 。。。哦不对,10s time.sleep(10)geturl.py 抓取网页连接这里的目的是抓取指定网站的所有链接,以每个一行的形式保存到txt文本中import re import requests # 获取网页内容 r = requests.get('http://note.coccoo.cc') data = r.text # 利用正则查找所有连接 link_list =re.findall(r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')" ,data) # 写入文本中 f = open("urls.txt",'wb') for url in link_list: f.write(url+'\n') f.close()运行脚本首先运行geturl.py获取网站链接库python geturl.py然后当前文件夹就会多出了一个urls.txt的文本,就是你的网站链接库让服务器自动帮你推送网站到百度nohup python curl.py &到此,任务就结束了,只不过每次网站更新后,你都需要重新运行第一步的脚本获取最新链接库所以我又把两个脚本合并一起,实时更新链接库并推送代码在此curl.zip直接解压后上传到服务器,执行nohup python curl.py &就可以了百度站长工具每天推送url的次数是5,000,000次,所以你要根据你网站中链接数量修改时间间隔,以免次数超纲,建议每分钟提交网站数量在 3400 以内注意事项:如果出现报错Traceback (most recent call last): File "geturl.py", line 3, in <module> import requests ImportError: No module named requests这是没有安装requests模块导致的,直接执行pip install requests安装就可以了如果这一句报错pip: command not found...,那就是你没安装pip,直接百度下根据你的系统安装python-pip比如 我的是Centos,安装命令yum -y install python-pip然后直接再继续执行就ok了
Python自动化实现主动推送站点到百度 在百度站长平台中,有各种方式可以提交自己的站点,以提高百度抓取自己网站的效率。此文章旨在使用主动推送(实时)提交到百度站长平台以提高网站曝光率。此方法是使用curl推送,所以在这里找到你的示例命令(前提是你要成为站长)然后我是在Linux上面执行的Python,其他平台此方法不适用。找个你喜欢的目录新建一个你喜欢的文件夹文件结构其实一共就两个文件,还有一个是自动生成的curl.py #用来执行自动推送geturl.py #抓取网站所有链接urls.txt #保存抓取的网站链接其中urls.txt是在执行 geturls.py 后自动生成,用以保存你要推送网站的所有链接代码curl.py#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 17/02/28 下午9:44 import os import time while True: ###### cmd = "你在百度站长中看到的curl推送示例命令" ###### cmd = "curl -H \'Content-Type:text/plain\' --data-binary @urls.txt \"http://data.zz.baidu.com/urls?site=note.coccoo.cc&token=xxxxxxxxxxxxxxx\"" os.system(cmd) # 休息间隔为 1s 。。。哦不对,10s time.sleep(10)geturl.py 抓取网页连接这里的目的是抓取指定网站的所有链接,以每个一行的形式保存到txt文本中import re import requests # 获取网页内容 r = requests.get('http://note.coccoo.cc') data = r.text # 利用正则查找所有连接 link_list =re.findall(r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')" ,data) # 写入文本中 f = open("urls.txt",'wb') for url in link_list: f.write(url+'\n') f.close()运行脚本首先运行geturl.py获取网站链接库python geturl.py然后当前文件夹就会多出了一个urls.txt的文本,就是你的网站链接库让服务器自动帮你推送网站到百度nohup python curl.py &到此,任务就结束了,只不过每次网站更新后,你都需要重新运行第一步的脚本获取最新链接库所以我又把两个脚本合并一起,实时更新链接库并推送代码在此curl.zip直接解压后上传到服务器,执行nohup python curl.py &就可以了百度站长工具每天推送url的次数是5,000,000次,所以你要根据你网站中链接数量修改时间间隔,以免次数超纲,建议每分钟提交网站数量在 3400 以内注意事项:如果出现报错Traceback (most recent call last): File "geturl.py", line 3, in <module> import requests ImportError: No module named requests这是没有安装requests模块导致的,直接执行pip install requests安装就可以了如果这一句报错pip: command not found...,那就是你没安装pip,直接百度下根据你的系统安装python-pip比如 我的是Centos,安装命令yum -y install python-pip然后直接再继续执行就ok了 -
Python在linux简单自动化工作 自动部署hexo到coding和github是酱紫,我用的是小书匠当做markdown编辑器,它可以自动把markdown源码同步到github,但是用github pages做hexo博客的话,于国内访问速度有点慢,于是打算用coding pages当做国内的hexo托管网站,github用做国外dalao浏览用 (如果有的话)。于是乎,我在想,能不能自动从github上clone源markdown文件,然后自动生成,部署到github pages和coding pages上。所以我把代码放到了一台闲置的服务器上,让它每天自动帮我同步。代码就如下了:#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 17/02/28 下午9:44 import os import time hexoMd = "/home/hexo/source/_posts" #hexo的md文件路径 hexo = "/home/hexo" #hexo根目录 xiaoshujiangPath = "/home/xiaoshujiang" #xiaoshujiang本地仓库存放路径 xiaoshujiang = "git@github.com:gty2012gty/xiaoshujiang.git" #xiaoshujiang的github仓库路径 while True: os.chdir("/home") if os.path.exists("xiaoshujiang"): #这里是旧的配置文件,存在先删除 os.system("rm -rf xiaoshujiang") #os.system("rm -rf "+hexoMd+"/*~") #删除hexoMd中备份的文件夹 while not os.path.exists(xiaoshujiangPath): #如果不存在就一直git clone os.system("git clone "+xiaoshujiang) os.system("rm -rf "+hexoMd+"/*") #删除原来的文章,以现有的为准,防止标题修改后出现文章重复 os.chdir(xiaoshujiangPath) os.system("rm -rf README.md") #删除不需要的README.md os.system("mv -bf * "+hexoMd) #移动到hexoMd os.chdir(hexo) os.system("hexo clean") #清除缓存 os.system("hexo g -d") #重新生成部署 ########################开始提交源代码################################ # os.system("git add -A") # os.system("git commit -am "+time.strftime('%Y-%m-%d',time.localtime(time.time()))) #提交说明改成当前日期 # os.system("git push source master:source") #提交到远程仓库的source分支 # time.sleep(180) #上一个任务执行完毕才会执行下一个,所以这句不需要 # os.system("hexo d") time.sleep(3600) #每小时执行一次让脚本在后台自动运行nohup python hexo.py &然后查看是否有这个进程ps -ef | grep hexo.py自动备份mysql:#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 16/10/30 下午9:04 import os import time user = 'root' #用户名 passwd = 'password' #密码 if not os.path.exists("/backup/sql"): os.mkdir("/backup/sql") while True: os.chdir("/backup/sql") #保存到/backup/sql文件夹下 #OVFile = 'ov-'+ str(time.time()) + '.sql' #已弃用 BlogFile = 'blog-'+ str(time.time()) + '.sql' #格式化blog数据库备份后的名称 os.system("mysqldump -u"+user+" -p"+passwd +" blog >"+BlogFile) #备份blog数据库 time.sleep(86400)说明默认一天备份一次,可以修改sleep的参数值,修改备份时间先修改密码然后vim databasedump.py填入密码nohup python databasedump.py &通过nohup运行程序后ps -ef | grep command kill -9 pid结束进程eg:ps -ef | grep databasedumo.py kill -9 pid以上,就用来举一反三吧。